PostgreSQL Introduction
This post is continuation of the series. If you do not have Postgres on your machine or sample data, you can read Installing PostgreSQL and Loading Sample Data post first.
First of all, we have to create a schema to manage easily our domain. It is in best practices, do not let dbo schema to seize your database. I use Navicat for my DDL operations but there are free softwares like pgAdmin.
1
create schema membership;
Functions use dollar signs to show scopes and language keyword for the language in the scope. We have a different datetime type here; TIMESTAMPTZ, timestamp with time zone. You must specify a time zone when inserting into a column with this type. Again, it is a best practice if you have inputs from different timezones. There are several ways to change it; Set timezone = ‘UTC’ in postgresq.conf or on connection, or in your queries.
1
2
3
4
5
6
7
8
9
create or replace function membership.random_string(len int) returns text as
$$
select substring(md5(random()::text), 0, len) as result;
$$ language sql;
create or replace function membership.the_time() returns TIMESTAMPTZ as
$$
select now() as result;
$$ language sql;
Create tables to continue. Another new data type for MSSQL developers; tsvector, a document in a form optimized for text search. We will use it later but we must fill it with data. You can create a trigger for insert and update operations in this table to update this column or write it in your insert statement. There is a bad practice like creating the tsvector column in select statement but it would be a performance loss. As you can view below, relations are a little bit different then MSSQL.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
create table membership.users(
id serial primary key not null,
user_key varchar(18) default membership.random_string(18),
email varchar(255) unique not null,
first varchar(50),
last varchar(50),
created_at timestamptz not null default membership.the_time(),
status varchar(10) not null default 'pending',
search_field TSVECTOR not null
);
create table membership.roles(
id serial primary key not null,
name varchar(50) not null
);
create table membership.users_roles(
user_id int not null references membership.users(id) on delete cascade,
role_id int not null references membership.roles(id) on delete cascade,
primary key(user_id, role_id)
);
This block creates a trigger to update our tsvector column with email, first and last data of the same table.
1
2
3
4
create trigger users_search_update_refresh
before insert or update on membership.users
for each row execute procedure
tsvector_update_trigger(search_field, 'pg_catalog.english', email, first, last);
We have our tables and trigger, let’s try it with insert statements.
1
2
3
4
5
6
7
8
insert into membership.users(email, first, last)
values ('test@test.com', 'Olcay', 'Bayram');
insert into membership.roles(name)
values ('Administrator');
insert into membership.users_roles(user_id, role_id)
values (1, 1);
We can query tsvector column with to_tsquery function. You can use Boolean operators in this query.
1
2
select * from membership.users
where search_field @@ to_tsquery('olcay & bay:*');
Create a view for your queries. I think biggest difference between SQL databases is TOP, LIMIT and ROWNUM. Postgres has LIMIT clause like MySQL.
1
2
3
4
create view membership.pending_users as
select * from membership.users where status = 'pending';
select * from membership.pending_users limit 10;
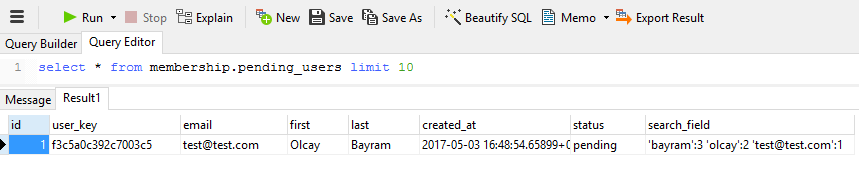
Do not forget to clean your test environment. Place this block at the beginning to prevent conflicts.
1
2
3
4
5
drop view if exists membership.pending_users;
drop table if exists membership.users_roles;
drop table if exists membership.users;
drop table if exists membership.roles;
drop schema if exists membership;
We will continue with NoSQL features of PostgreSQL next time.